賃貸管理支援事業家主管理・精算管理プロダクト開発チームです。
管理支援領域では複数のサービスを開発しており、それぞれのサービス間で情報をやりとりし合っています。 今回はサービス間の情報のやりとりをWebhookを利用して行ったことで得たナレッジを共有します。
Webhookって何?
Webhook は Web アプリケーションに対して、特定のイベントが発生したら別の Web アプリケーションへ自動で通知を発行する仕組みです。 名前の由来としては「Web」と、特定のイベント発生時に処理が「フックされる」(自動的に引き起こされる)ことを意味する「Hook」を組み合わせて Webhook と呼ばれています。 ちなみに、Webhook はイベント発生の「波」を捉え、その情報を HTTP POST リクエストという「矢印」で指定の URL へ通知するのを表現しているロゴが広く利用されています。

Webhook が登場する以前のシステム連携では、変化を確認するためにシステムが定期的に「問い合わせに行く」ことが多かったようです。これがポーリングです。
しかし、2000年代半ばから「Webコールバック」として発展した Webhook はイベント発生時にシステムが自ら「お知らせ」を届ける「イベント駆動型アーキテクチャ」というアプローチをとっています。
これによって定期的な問い合わせの必要がなくなり、通知があった場合のみ問い合わせすることでリソース消費を抑えられ素早くデータ連携ができるようになっています。
APIとの違いは?
WebhookとAPIはどちらも異なるシステムの間でデータをやり取りするための仕組みですが、イベントの発生方法に違いがあります。
APIはプル型で、クライアント側(データを必要とする側)がサーバー側(データを持っている側)に対し、「この情報が欲しい」とリクエストを送信します。
例えると、お客さん(クライアント)がレストランでメニューを見て「これください」と注文(リクエスト)し、店員さんが料理(レスポンス)を持ってきてくれるイメージです。
それに対し、Webhookはプッシュ型で、サーバー側(イベントが発生した側)がクライアント側(通知を受け取る側)に対し、「こんなイベントが起きましたよ」と能動的に通知を送信します。
- クライアントがリクエストをして、レスポンスを同期的に受け取る(プル型)
- クライアントからのリクエストを受け取ったサーバーが何らかの処理を行ったタイミングで情報をほかのサーバーへ送信する。他のサーバーから見たらイベント発生時に リクエストされる(プッシュ型)
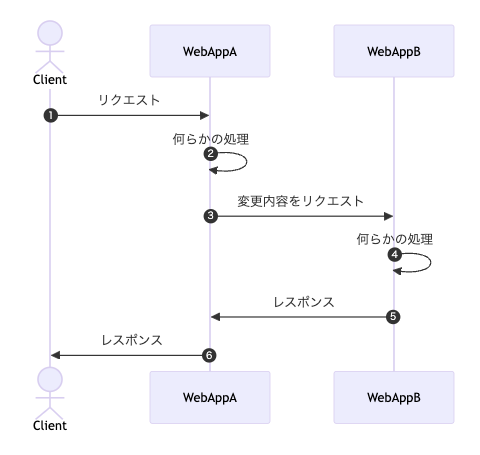
私たちは③~⑤の処理をバックグランドジョブで管理することにしました。 これはWebhookリクエストの失敗時の情報の確認やリトライの仕組みを既存の非同期処理管理の仕組みで行うことで、新たに管理のための開発を省略するためです。
なぜ非同期処理を利用するのか?
私たちは後で処理を行うことよりも失敗時の情報の確認やリトライの仕組みを簡単に用意するためにRuby on Railsが提供するバックグランドジョブの仕組みを利用することにしました。例えば Sidekiq や ActiveJob の mission_control を利用することでバックグランドジョブの管理をブラウザの画面上から行うことができます。Webhookリクエストの滞留状態の確認や失敗時の対向システムのレスポンスの確認、一時的な問題であれば手動でのリトライが可能になります。
ですが、そもそも非同期処理とはなんでしょうか?
Web アプリケーションにおいて非同期処理とはなんらかのリクエストを実行して「後で」処理が行われることです。一方で同期処理はなんらかのリクエストを実行して「すぐ」に処理が行われることです。
私たちが実装したWebhookは特定のリクエストがすぐに処理が実行されるのではなく後でバックグラウンドで実行されるジョブでWebhookリクエストを処理させたので非同期処理に分類されます。
非同期処理のメリットは同期処理とは違って処理の完了を待たずにあたかも処理が完了したように見せることができることです。 ですので、対向システムのレスポンスが長い時間がかかったとしてもエンドユーザーを待たせることをせずに処理を完了させたようにみせることができます。 この点も非同期処理を利用することのメリットと感じています。
どうやったか?
私たちには複数サービス間のリアルタイムでデータの連携を行いたいという要望がありました。サービス間のデータの連携における実装は以下のようになります。
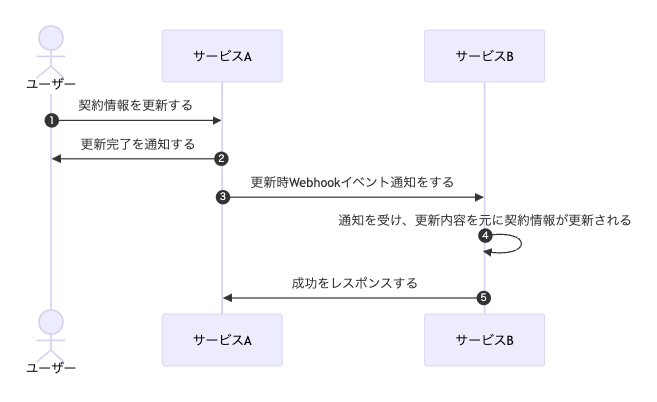
なぜWebhookだったか?
たとえば連携のリクエストを都度開発する場合を考えます。「作成時はこのURL、更新時は別のURL」といった機能ごとの変更や、新しい外部サービス連携、通知先URLの変更など、ビジネス上の要求は多岐にわたります。また後の拡張によってあたらしい通知先URLが追加・変更・削除されることも考えられます。これら全ての変更があらたな開発タスクとなり、都度のコード修正・テスト・デプロイという開発サイクルを経る必要があり、結果として軽微な設定変更がビジネスのボトルネックになってしまいます。
複数の顧客(テナント)が利用するマルチテナントのSaaSでは、「A社はエンドポイントXに、B社はエンドポイントYに同じイベントを通知したい」という要求はごく自然に発生します。顧客が増えるたびにコード上で条件分岐を増やしていくのは非現実的であり、コードベースの複雑化とメンテナンス性の著しい低下も避けたいと考えました。
これらの課題はふるまいを都度足していく考え方が根本にあると考え、Webhookのエンドポイント情報をデータベースで管理し、最終的にはその設定を管理画面から操作できるようにするアプローチを採用しました。
この「設定のデータ化」を実現するテーブルは、以下のようなカラムで構成されています。
| カラム名 | データ型 | 説明 |
|---|---|---|
| subject | string | プロダクトのモデル名 |
| action_name | integer | 受け取るプロダクトのアクション名(create,update等) |
| http_request_method | integer | リクエストするHTTPリクエストメソッド |
| auth_method | integer | 認証方法 |
| end_point | string | リクエストするエンドポイント |
| company_id | integer | 会社ID |
- subject と action_name: どのようなイベント(例: 管理委託契約の更新時)が発生したときにWebhookを送信するかを定義します。これにより、イベントの種類に応じた柔軟なルーティングが可能になります。
- end_point と http_request_method: 通知先のURLとHTTPメソッド(POST, PUTなど)をデータとして保持します。これがハードコーディングをなくすための中心的なカラムです。
- auth_method: 認証方式の「種別」を管理しておくことで、様々な認証タイプのWebhookに対応できるようにしています。
- company_master_id: どの企業に紐づく設定なのかを識別します。これにより、前述の「お客様ごとに異なるエンドポイントに通知したい」という要望を実現することができます。
これらのWebhookのエンドポイント情報を管理画面で設定できるようにしたことにより、ふるまいを後から追加せずに複数サービス間のデータの連携処理を実現することができました。
Webhook以外の選択肢は?
Webhook以外の選択肢もチーム内で検討されていました。
Webhookとよく比較される技術はPolling、Message Queue、Pub/Subなどがあります。
Pollingとは、クライアントが定期的にサーバーに「新しい情報ありますか?」と聞き続ける方式です。使用例としては、チャットアプリで5秒ごとにサーバーに新しいメッセージがあるか確認することなどがあります。仕組みは簡単ですがリクエストが定期的に発生し続けることがネットワークやサーバーには負荷が懸念です。リクエストとリクエストの間にサーバー・クライアント間の情報の不整合が発生する可能性があります。
Message Queue (Kafka, AWS Kinesisなど)は、クライアントがすべきことを「メッセージ」という名前でキューに入れ、サーバー側で一つずつ処理する方式です。短時間に大量のメッセージの書き込みを行うことに強いメリットがあります。プロデューサー・コンシューマー・(ブローカー)のアプリケーションがそれぞれに必要になるため、実装や運用のコストが私たちにとって高いのがデメリットです。
Pub/Subはサーバー側の情報が変更されると複数の購読者が同時に受け取る方式です。ニュース通知のように同じ情報を複数のクライアントに配信する必要がある場合は効率的です。しかし、Pub/Sub専用のシステム(AWS SNSなど)を導入して管理すること、そのメンテナンスが私たちにとって高いのがデメリットです。
他の技術に比べて、Webhookを導入する場合は既存のバックエンドサーバー(Ruby on Rails)にすでにあるバックグラウンドジョブの仕組みを利用することで、失敗ジョブの確認やリトライの仕組みを新たに開発・追加する必要がないというメリットがあったため、Webhookを選択することにしました。
Webhookのテストはどうしたか?
Webhookは外部サービスとの通信を前提にしたテストが必要になります。 このような場合に考えるべきは、外部依存をどう扱うかという点です。
実際の外部サービスに依存したテストには以下のような問題があります:
- テスト実行のたびに外部サービスへの通信が発生し、テストが不安定になる
- 外部サービスのメンテナンスやネットワークの問題でテストが失敗する可能性がある
- エラー状態(401認証エラー、500サーバーエラーなど)を意図的に発生させるのが困難
- テスト実行速度が外部サービスのレスポンス時間に左右される
そこで私たちは、外部依存を適切に分離・制御できる以下の2つのアプローチでテストを実装しました。
1. Mockを利用したユニットテスト
既存のテストと同様に、Mockを活用してその機能のシナリオに対するユニットテストを実施しました。
# RSpecテストコードの例 describe '正常系' do let!(:expected_params) { { ... } } before do allow(HttpClient).to receive(:request).and_return(Net::HTTPSuccess.new(1.0, '200', 'OK')) end it '期待したパラメータでWebhookリクエストが発行される' do DatalinkageJob.new.perform expect(HttpClient).to have_received(:request) .once .with( method: :post, uri: 'https://example.itandi.co.jp', headers:, # 認証ヘッダーの生成ロジックを検証 params: expected_params # パラメータの組み立てロジック ) end end describe '認証失敗時' do before do allow(HttpClient).to receive(:request).and_return(Net::HTTPUnauthorized.new(1.0, '401', '認証エラー')) end # ... end describe 'APIサーバーのエラー' do before do allow(HttpClient).to receive(:request).and_return(Net::HTTPInternalServerError.new(1.0, '500', 'サーバーエラー')) end # ... end
2. ローカルでの結合テスト
私たちのチームはコンテナ内からホストマシンにアクセスするための特殊なDNS名を利用して結合テストを行いました。両方のサービスをローカル環境が動作させて、下記を利用してWebhookリクエストを発行し、検証を行いました。
host.docker.internal:{Port}
おわりに
いかがでしたでしょうか?
複数のサービス間の情報のやりとりを扱いやすくすることを目指してWebhookを利用することで得たナレッジを改めてチームでまとめてみることで知識が統合された実感を得ました。 皆さんの開発プロジェクトでも、外部サービスとの連携や非同期処理の導入を検討する際には、ぜひWebhookの活用を考えてみてください。
今後のみなさまのサービス間の連携処理にこの記事が役立てば幸いです!!