横澤です、いつもお世話になっております。
本当は5月に書こうと思っていたネタなのですが、最近は時空の歪みの影響を強く受ける事があり気づいたら6月になってしまいました。
本題です、本エントリではData Pipelineを使ってRDSデータをS3にエクスポートし、去年のre:inventで発表のあったAthenaを使ってDWHっぽいものを作ってみるエントリです。Athenaについては説明記事やチュートリアル記事が沢山あるので気になったらググって見て下さい。Data Pipelineはデータ処理に特化したワークフローエンジンの様なサービスです。名前の通りデータの抽出や加工、集約等についてAWS内部の様々なリソースを活用してワークフローを組み立てる事が出来ます。今回はRDS(MySQL)に入ってるデータをCSVファイルとしてS3に吐き出す部分をData Pipelineで実行し、Athenaで読み込めるようにしてみました。
【最初の1分:ジョブの登録】
RDSからS3にCSVを出力する処理はテンプレートが用意されているので簡単に作成できます。  テンプレートを選択したらDBへの接続情報、バッチスケジュール、S3のバケットを指定すれば初期設定は完了です。
テンプレートを選択したらDBへの接続情報、バッチスケジュール、S3のバケットを指定すれば初期設定は完了です。
このタイミングで幾つか注意点があります。
- Athenaは現時点(2017-06-08)ではUSリージョンのみサービス提供となっているので、読み込み先となるS3バケットもUSリージョンに作成する必要があります。
-
Data Pipelineは「DataPipelineDefaultRole」と「DataPipelineDefaultResourceRole」というロールを使うのでこれらにS3やRDSへのアクセス権を付与する必要があります
-
データエクスポートを実行するEC2インスタンスについて、デフォルトだとt1.microが選ばれていますがt系インスタンスはVPC上への作成がデフォなので接続先がVPCに置かれていない場合はm系のインスタンスを使うなどの工夫が必要です
【間の1分:ジョブの編集】
登録されたジョブはこのような感じでワークツリーで可視化されます、それぞれのタスクを選択すると右側でconfigを修正する事が出来ます。  RDSでsubnetを設定している場合はEc2Resourceタスクを開いてオプションでsubnet-idを設定しないとconnectionエラーになってしまいます。またEC2からRDSへ上手く接続出来ない時にはデバッグ目的でEC2にsshで入りたくなる事もあるのでキーペアも登録しておくと後々幸せになれるかもです。
RDSでsubnetを設定している場合はEc2Resourceタスクを開いてオプションでsubnet-idを設定しないとconnectionエラーになってしまいます。またEC2からRDSへ上手く接続出来ない時にはデバッグ目的でEC2にsshで入りたくなる事もあるのでキーペアも登録しておくと後々幸せになれるかもです。
【最後の1分:Athenaでクエリ発行】
これでジョブは登録されたのでスケジュールをon-demandに設定してactivateするとワークフローが実行され、成功するとS3にCSVが吐き出されます。ワークフローエンジンらしく各ジョブはこんな感じで結果成否やログが見れるのでハマった時も修正がかけやすいです。  最後にAthenaのQueryEditorを使ってHiveQL形式のCREATE TABLE文を発行すればDWHっぽいテーブルの完成です!一点ハマったポイントとしてLOCATIONは「s3://[バケット名]/[パス名]」と指定しなければならず、当初はリージョンURLを含めて指定していたせいでエラーが起きてました・・・
最後にAthenaのQueryEditorを使ってHiveQL形式のCREATE TABLE文を発行すればDWHっぽいテーブルの完成です!一点ハマったポイントとしてLOCATIONは「s3://[バケット名]/[パス名]」と指定しなければならず、当初はリージョンURLを含めて指定していたせいでエラーが起きてました・・・ 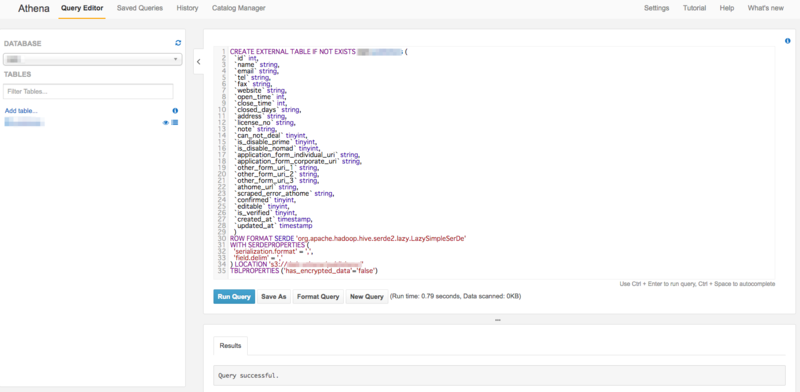
以上で3分クッキングは完了です、実際にはもっと時間かかりましたが本記事を読んで頂く事で3分くらいで作れるようになると嬉しい限りです。そしてここまで書いておいてなんですが、イタンジではDWHっぽい事を実現するツールとしてはGoogle Big Queryを使っており、最近はDigdagというワークフローエンジン経由でembulkを動作させてData Pipelineと似たような事をやっています。なので今回はあくまでもData PipelineとAthenaを実験する目的でやってみた的なネタなので実運用するとどうなるかは未知数だったりします。
イタンジ株式会社ではこのようなデータエンジニアリングにテンションが上がるエンジニアや、集約管理されたデータを使って探索的にデータ解析したいエンジニアを募集しております。