これは日本情報クリエイト Engineers Advent Calendar 2016の24日目の記事です。 元日本情報クリエイトのエンジニアなのでOB枠として参加させてもらいます!
日本情報クリエイトは宮崎で不動産系の自社プロダクトを開発し、日本全国に販売している会社です。 九州にUターンを考えている方、九州の南のほうにお住まいのエンジニアの方、転職先としておすすめです。
はじめに
皆さんクローラー作ってますか? 以前こちらにも書きましたがscrapy + scrapy cloudを使うと簡単に安定稼働するクローラーを構築できます。 今日はscrapy cloudを提供しているscraping hubが展開しているもう一つのサービスcrawleraをご紹介します
crawleraとは
英語ですがここのページに記載されています。 https://crawlera.com/
簡単にまとめると以下の様なことを実現出来るクローラー専用のproxyサービスです
- 数千のIPプールを介してのリクエスト
- 50カ国以上のIPが利用可能
- 130種類以上のステータスコード、またはキャプチャを含むバンの自動検出
- 自動再実行及び、遅延処理でリクエストを抑制してバンを防ぐ
- HTTPとHTTPSをサポート
便利ですね、ipの付け替えやバンの検出及び自動再実行を自前でやろうとするとそれなりにコストがかかりますがその辺をまるっとやってくれます。
使ってみよう
以下の物が必要です。
- scrapinghubのアカウント
- クレジットカード(crawleraは無料版がないため料金の支払いが必要です)
https://scrapinghub.com/にアクセスしてアカウントを作成し、crawleraを契約してください。
crawleraのアカウントを作る
Create Accountをクリックします

アカウント名を入力してリージョンを選択します。 ここで選択したリージョンのIPアドレスが使用されます。 allを選択すると各国のIPプールの中でIPを付け替えてくれます。 今回は日本を選択します。

作成するとOverviewが表示されます、ここではcrawleraでリクエストしたものがどれくらいバンされたり失敗したのかやどこのサイトにどれくらいアクセスしたのかをグラフで確認出来ます。 また残り何回リクエスト出来るかもここで確認出来ます。

使ってみる
作成したcrawleraアカウントの設定画面にcurlを使ったコマンド例があります、これをコマンドラインに貼り付けて実行してみます。
curl -U [API KEY]: -x proxy.crawlera.com:8010 http://httpbin.org/ip
するとリクエスト元のIPアドレスがjsonで返ってきます。 試しに何回か実行すると毎回違うIPが返ってくることがわかります、crawleraさんがちゃんとプールされたIPの中から毎回違うIPをチョイスしてくれてますね。
実行後実行したアカウントをcrawleraの管理画面から選択するとリクエストの履歴を見ることが出来ます。 client ipから実際にリクエストで使ったipレスポンスタイム等必要な情報を全て見ることが出来ます。

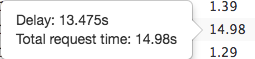
また各行のResp. Timeにマウスオーバーするとどれくらい遅延を入れたかが表示されます。 crawleraさんが自動で遅延処理を入れてくれていることが分かります。
後は今使っているクローラーのproxyにcrawleraを指定すれば完了、簡単ですね。 scrapyをお使いの場合は専用のライブラリが用意されているのでpip installして設定するだけです。 詳細はこちらに記載されています。
https://doc.scrapinghub.com/crawlera.html
終わりに
いかがでしたか、crawleraを使うと拍子抜けするほど簡単にクローリングを最適実行する環境とダッシュボードを手に入れることが出来ます。 ただ実際に稼働しているクローラーに入れたところパフォーマンスが1/3まで低下してしまいました。 これはcrawleraが自動で遅延処理を入れてくれるのはいいんですが15秒とか平気で遅延させるためです。 パフォーマンスが求められるクローラーの場合はただ入れるだけだと大変なことになるので同時リクエスト数を増やす等のチューニングが必要です。